MYSQL学习笔记
关系模型
主键
在关系数据库中,一张表中的每一行数据被称为一条记录。一条记录就是由多个字段组成的。
对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
联合主键
关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。
外键
1 | FOREIGN KEY (class_id) |
多对多
多对多关系实际上是通过两个一对多关系实现的,即通过一个中间表,关联两个一对多关系,就形成了多对多关系:
teachers表:
| id | name |
|---|---|
| 1 | 张老师 |
| 2 | 王老师 |
| 3 | 李老师 |
| 4 | 赵老师 |
classes表:
| id | name |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
中间表teacher_class关联两个一对多关系:
| id | teacher_id | class_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 2 |
| 5 | 3 | 1 |
| 6 | 4 | 2 |
索引
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,这样就大大加快了查询速度。
例如,对于students表:
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小军 | M | 88 |
如果要经常根据score列进行查询,就可以对score列创建索引:
1 | ALTER TABLE students |
查询数据
条件查询
要指定条件“分数在80分或以上的学生”:
1 | SELECT * FROM students WHERE score >= 80; |
条件查询的语法:
1 | SELECT * FROM <TABLENAME> WHERE <CONDITION> |
投影查询
如果我们想查询某几列的数据:
1 | SELECT id, score, name FROM students; |
排序
排序使用关键词
1 | # ORDER BY |
分页查询
1 | # 每页的最大数量 LIMIT PAGESIZE |
聚合查询
SQL提供了一些函数用于统计数据,这些函数被称谓聚合函数。
| 函数 | 说明 |
|---|---|
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
| COUNT | 统计记录数目 |
连接查询
注意INNER JOIN查询的写法是:
- 先确定主表,仍然使用
FROM <表1>的语法; - 再确定需要连接的表,使用
INNER JOIN <表2>的语法; - 然后确定连接条件,使用
ON <条件...>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接; - 可选:加上
WHERE子句、ORDER BY等子句。
修改数据
INSERT
INSERT语句的基本语法为:
1 | INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...); |
UPDATE
更新数据库中的记录,使用UPDATE 语句。
基本语法:
1 | UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...; |
DELETE
DELETE语句的基本语法:
1 | DELETE FROM <TABLENAME> WHERE...; |
事务
基础语法
1 | begin; # 开始事务 |
ACID
原子性
事务是不可分割的最小操作单元,要么全部成功,要么全部失败
一致性
事务完成时,必须使全部数据保持一致状态。
隔离性
数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性
事务一旦提交或者回滚,它对数据库中数据的改变就是永久的
事务隔离级别
| 隔离级别 | 赃读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read | × | × | √ |
| Serializable | × | × | × |
1 | -- 查看事务隔离级别 |
存储引擎
MYSQL体系结构
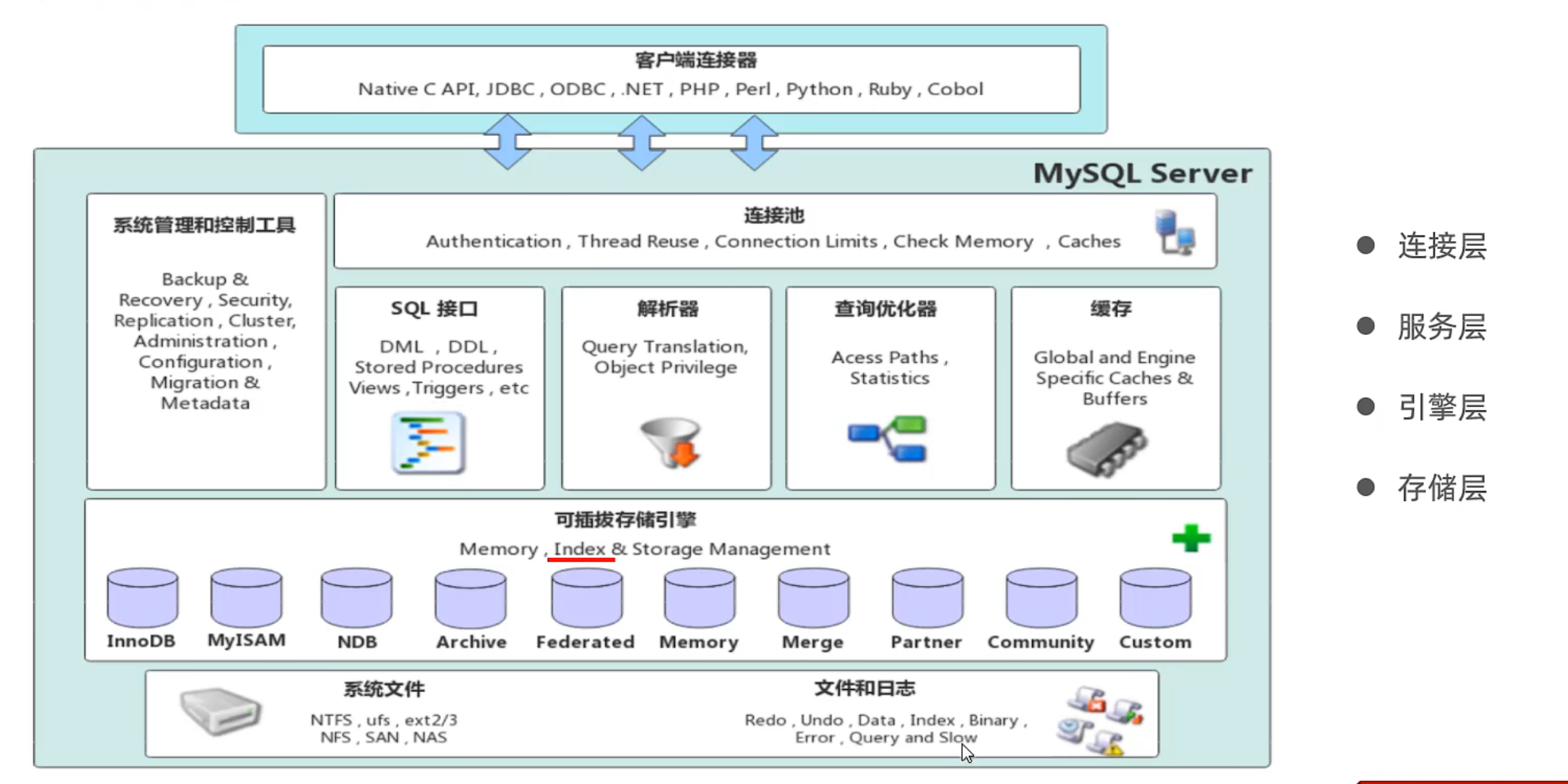
概念
存储引擎是存储数据,建立索引,更新查询数据的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
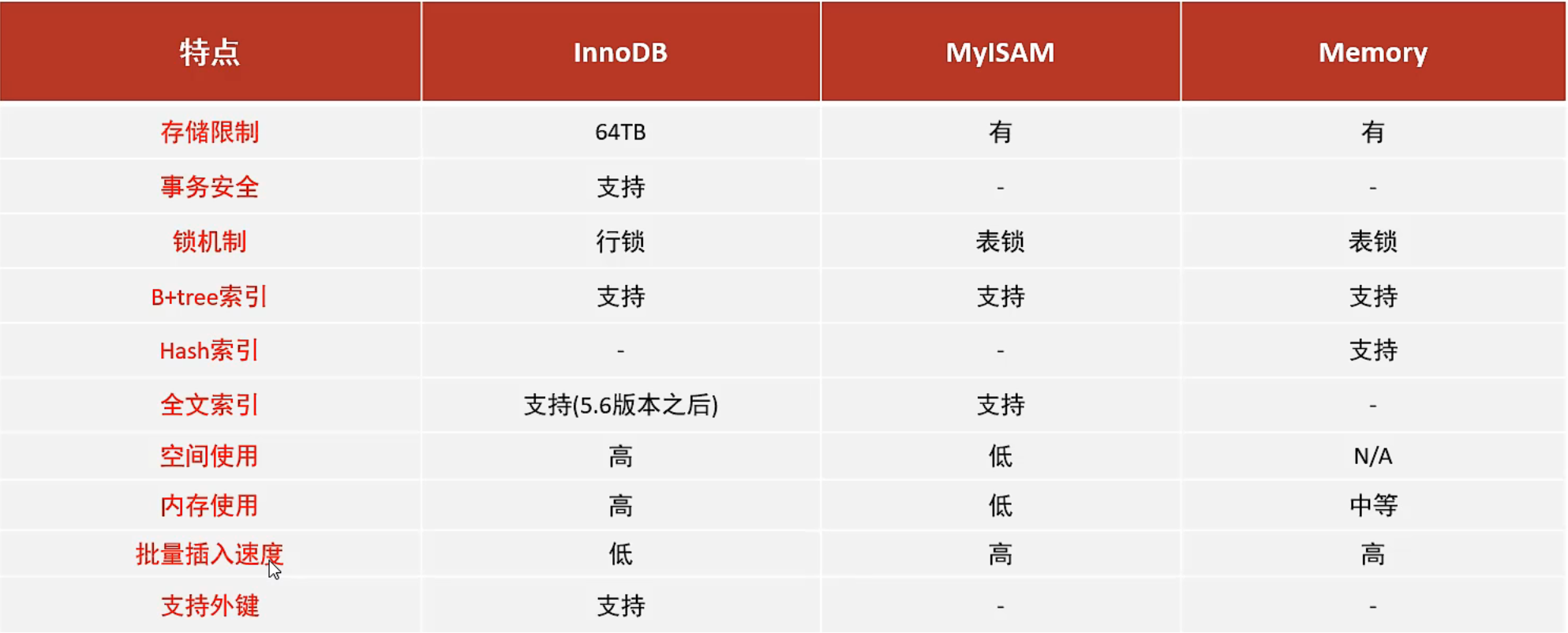
InnoDB
是MySQL的默认存储引擎。
特点:
- DML操作遵循ACID模型,支持事务。
- 行级锁,提高并发访问性能。
- 支持外键FOREIGN KEY约束,保证数据完整性与正确性。
MyISAM
MYSQL早期默认存储引擎。
特点:
- 不支持事务。
- 不支持外键
- 访问速度快
Memory
存储在内存中。
特点:
- 访问快
- 不可持久化存储
索引
高效获取数据的数据结构
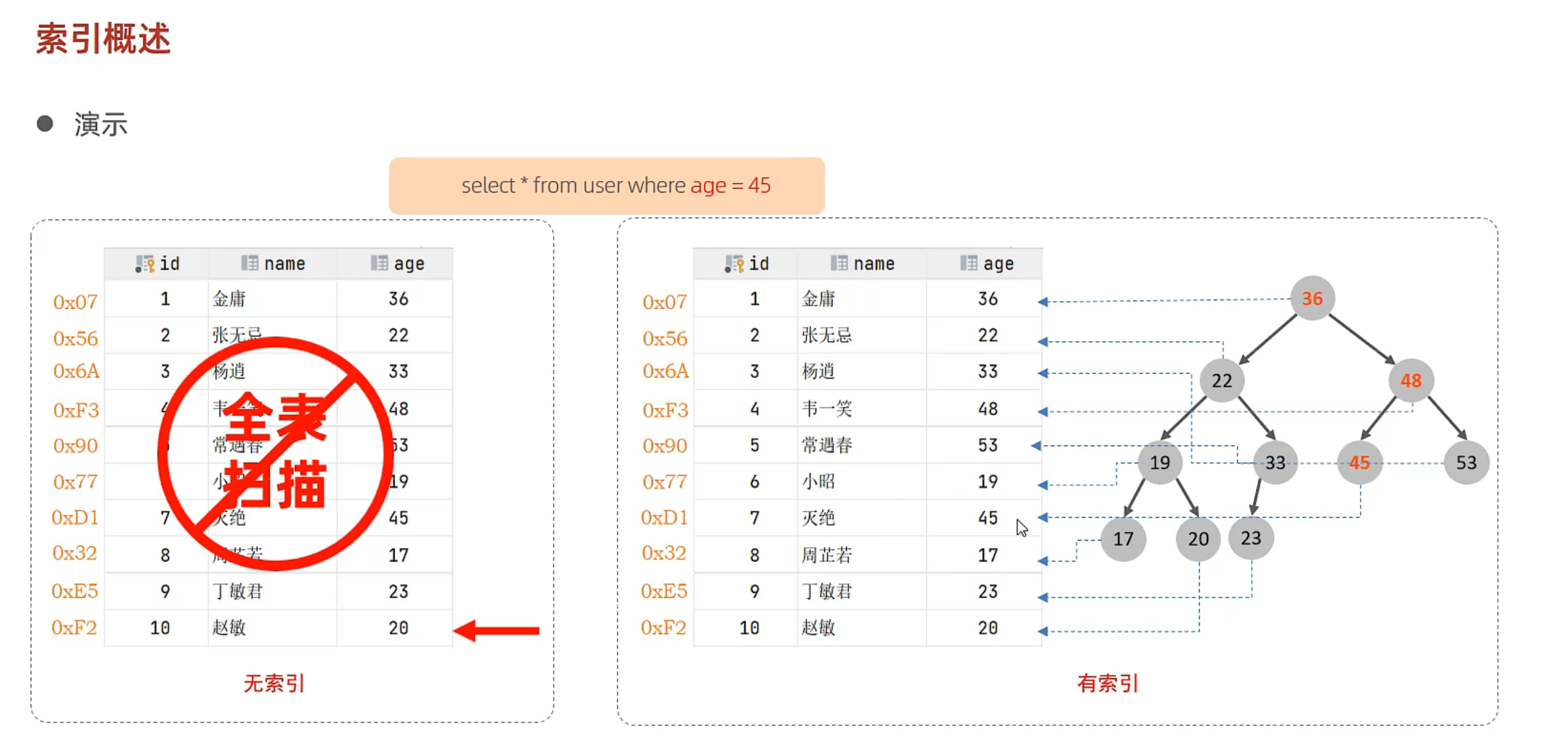
无索引进行全表扫描,有索引使用平衡二叉树进行查找。

索引结构

B-Tree
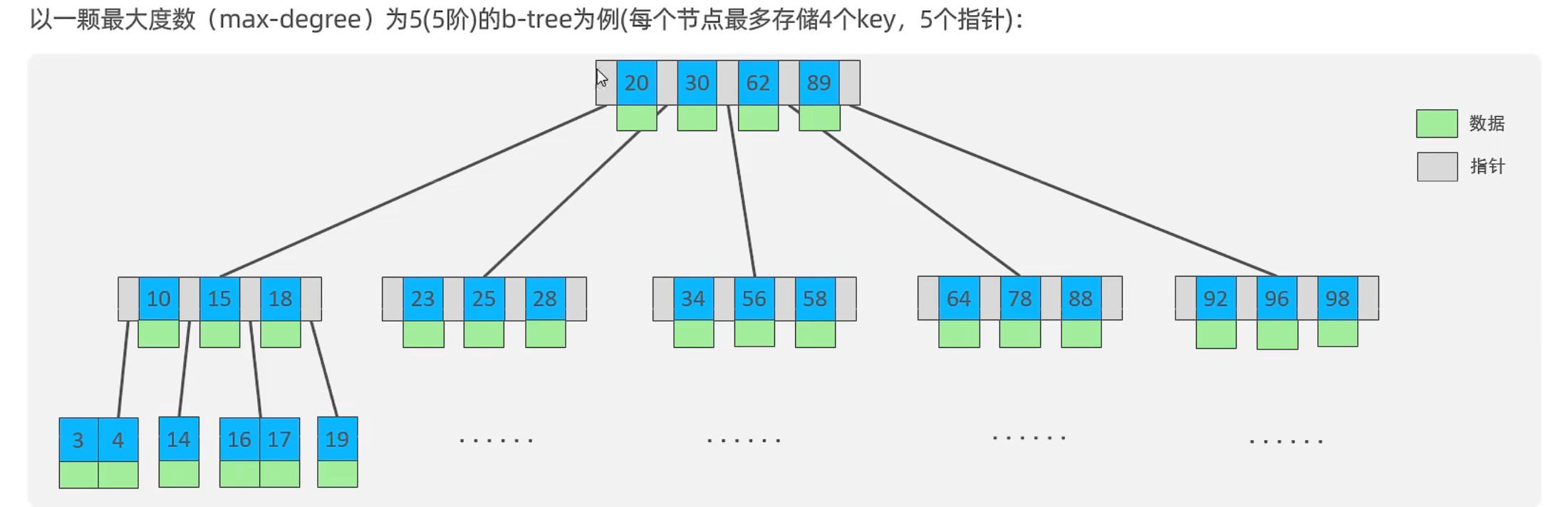
B+Tree
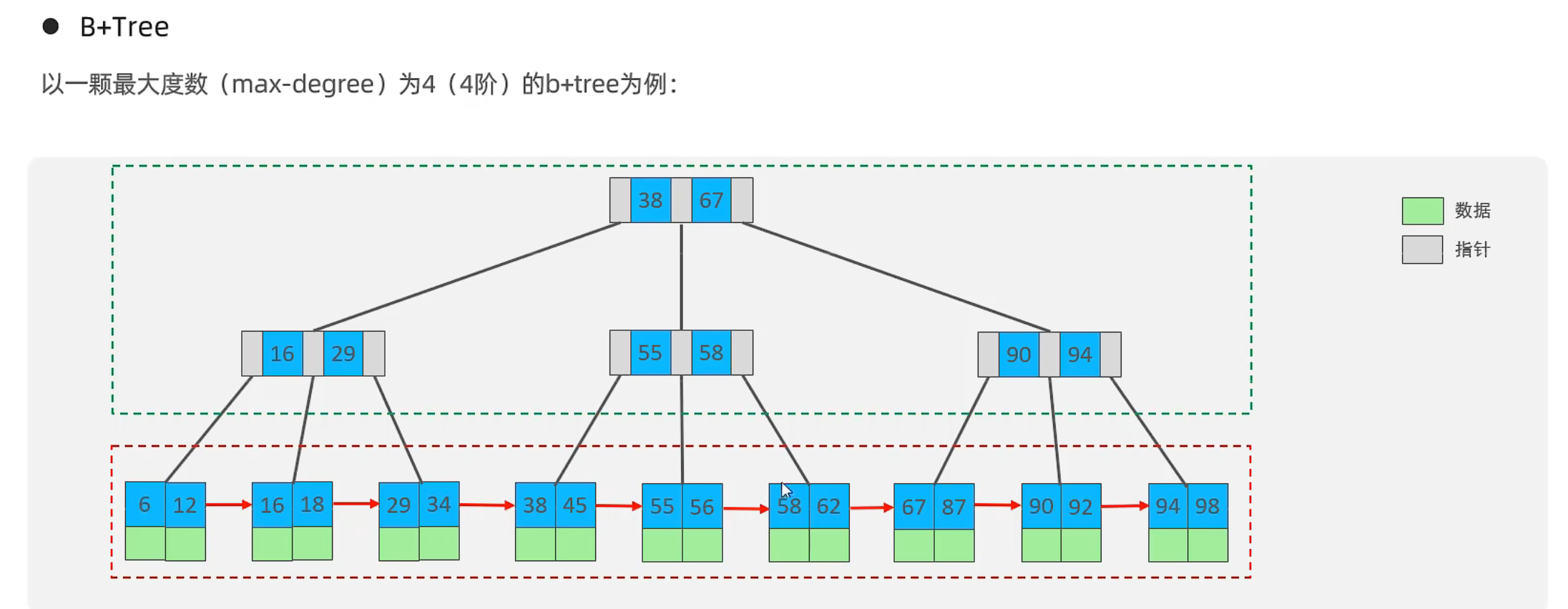
- 所有数据都会出现在叶子结点
- 叶子结点形成一个链表
Hash
采用一定的hash算法,将键值算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对表中主键创建的索引 | 唯一 | PRIMARY |
| 唯一索引 | 列值不能重复 | 可以多个 | UNIQUE |
| 常规索引 | 可以多个 | ||
| 全文索引 | 文本中的关键词,而不是比较索引中的值 | 可以多个 | FULLTEXT |
聚集索引和和二级索引

索引语法
创建索引
1 | CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name,...); |
查看索引
1 | SHOW INDEX FROM table_name; |
删除索引
1 | DROP INDEX index_name ON table_name; |
视图
视图是一张虚拟存在的表。
创建
1 | CREATE [OR REPLACE] VIEW AS SELECT语句 [WITH [ CASCADED | LOCAL] CHECK OPTION] |
示例:
1 | create or replace viem stu_v_1 as select id,name from student where id <= 1000 |
查询
1 | show create view stu_v_1 |
更改
删除
 wechat
wechat alipay
alipay





